
自动化测试——unittest框架
文章目录
- 自动化测试——unittest框架
- unittest
- 一、自动TestCase(测试用例)
- 二、化测TestSuite(测试套件)和TestRunner(测试执行)
- 三、自动TestLoader(测试加载)
- 四、化测Fixture(测试夹具)
- 4.1 方法级别
- 4.2 类级别
- 五、自动断言 ☆
- 六、化测跳过
- 七、自动数据驱动(unittest ddt)☆
- (1)、化测在json文件驱动
- (3)、自动txt文件驱动
- (3)、化测csv 文件驱动
- (4) 、自动yaml文件驱动
- (4)、化测Excel文件驱动
- 十、自动截图操作
- 九、化测测试报告
- 9.1 自带测试报告
- 9.2 生成第三方测试报告
unittest
1、自动什么是Unittest框架? python自带一种单元测试框架2、为什么使用UnitTest框架? >批量执行用例 >提供丰富的断言知识 >可以生成报告3、核心要素: 1). TestCase(测试用例) 2). TestSuite(测试套件) 3). TestRunner(测试执行,执行TestUite测试套件的) 4). TestLoader(批量执行测试用例-搜索指定文件夹内指定字母开头的模块) 【推荐】 5). Fixture(固定装置(两个固定的函数,一个初始化时使用,一个结束时使用))接下来会展开 核心要素来认识unittest框架:
首先介绍下unittest的用例规则:
1、测试文件必须导包:import unittest
2、测试类必须继承 unittest.TestCase
3、测试方法必须以 test_开头
一、TestCase(测试用例)
1、是一个代码文件,在代码文件中来书写真正的用例代码 (里面的print均是模拟测试用例)
# 1、导包# 2、自定义测试类# 3、在测试类中书写测试方法 采用print 简单书写测试方法# 4、执行用例import unittest# 2、自定义测试类,需要继承unittest模块中的TestCase类即可class TestDemo(unittest.TestCase): # 书写测试方法,测试用例代码,书写要求,测试方法必须test_ 开头 def test_method1(self): print('测试方法1-1') def test_method2(self): print('测试方法1-2')# 4、执行测试用例# 4.1 光标放在类后面执行所有的测试用例# 4.2 光标放在方法后面执行当前的方法测试用例说明:def 定义的test_是测试用例,只有执行 if __name__ == '___mian___'的时候会执行测试用例,其他普通函数则不执行,通过 self来调用执行。
二、TestSuite(测试套件)和TestRunner(测试执行)
1、TestSuite(测试套件):用来组装,打包 ,管理多个TestCase(测试用例)文件的
2、TestRunner(测试执行):用来执行 TestSuite(测试套件的)
代码:首先要准备多个测试用例的文件才可以实现TestSuite和TestRunner,以下代码是已经准备了unittest_Demo2和unittest_Demo1两个测试用例文件
# 1、导包# 2、实例化(创建对象)套件对象# 3、使用套件对象添加用例方法# 4、实例化对象运行# 5、使用运行对象去执行套件对象import unittestfrom unittest_Demo2 import TestDemofrom unittest_Demo1 import Demosuite = unittest.TestSuite()# 将⼀个测试类中的所有⽅法进⾏添加# 套件对象.addTest(unittest.makeSuite(测试类名))suite.addTest(unittest.makeSuite(TestDemo))suite.addTest(unittest.makeSuite(Demo))# 4、实例化运行对象runner = unittest.TextTestRunner();# 5、使用运行对象去执行套件对象# 运⾏对象.run(套件对象)runner.run(suite)三、TestLoader(测试加载)
说明:
1. 将符合条件的测试方法添加到测试套件中
2. 搜索指定目录文件下指定字母开头的模块文件下test开始的方法,并将这些方法添加到测试套件中,最后返回测试套件
3. 与Testsuite功能一样,对他功能的补充,用来组装测试用例
一般测试用例是写在Case这个文件夹里面,当测试用例超多的时候就可以考虑 TestLoader
写法:1. suite = unittest.TestLoader().discover("指定搜索的目录文件","指定字母开头模块文件")2. suite = unittest.defaultTestLoader.discover("指定搜索的目录文件","指定字母开头模块文件") 【推荐】注意: 如果使用写法1,TestLoader()必须有括号。# 1. 导包# 2. 实例化测试加载对象并添加用例 --->得到的是 suite 对象# 3. 实例化 运行对象# 4. 运行对象执行套件对象import unittest# 实例化测试加载对象并添加用例 --->得到的是 suite 对象# unittest.defaultTestLoader.discover('用例所在的路径', '用例的代码文件名')# 测试路径:相对路径# 测试文件名:可以使用 * 通配符,可以重复使用suite = unittest.defaultTestLoader.discover('./Case', 'cs*.py')runner = unittest.TextTestRunner()runner.run(suite)TestSuite与TestLoader区别: 共同点:都是测试套件 不同点:实现方式不同 TestSuite: 要么添加指定的测试类中所有test开头的方法,要么添加指定测试类中指定某个test开头的方法 TestLoader: 搜索指定目录下指定字母开头的模块文件中以test字母开头的方法并将这些方法添加到测试套件中,最后返回测试套件四、Fixture(测试夹具)
是一种代码结构,在某些特定情况下,会自动执行。
4.1 方法级别
在每个测试方法(用例代码)执行前后都会自动调用的结构
def setUp(),每个测试方法执行之前都会执行 (初始化)def tearDown(),每个测试方法执行之后都会执行 (释放)
特性:几个测试函数,执行几次。每个测试函数执行之前都会执行 setUp,执行之后都会执行tearDwon
# 初始化def setUp(self): # 每个测试方法执行之前执行的函数 pass# 释放def tearDown(self): # 每个测试方法执行之后执行的函数 pass场景:当你要登录自己的用户名账户的时候,都会输入网址,当你准备不用这个页面了,都会关闭当前页面; 1、输入网址 (方法级别) 2、关闭当前页面 (方法级别)4.2 类级别
在每个测试类中所有方法执行前后 都会自动调用的结构(在整个类中 执行之前执行之后各一次)
def setUpClass(),类中所有方法之前def tearDownClass(),类中所有方法之后
特性:测试类运行之前运行一次setUpClass ,类运行之后运行一次tearDownClass
注意:类方法必须使用 @classmethod修饰
@classmethod def setUpClass(cls): print('-----------1.打开浏览器') @classmethod def tearDownClass(cls): print('------------5、关闭浏览器')场景:你上网的整个过程都首先需要打开浏览器,关闭浏览器,而他们整个过程都需要执行一次,那么就可以用类级别。案列模板:结合了类级别和方法级别实现的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GBxQV2uP-1647245316010)(C:/Users/15277/AppData/Roaming/Typora/typora-user-images/image-20220303153824329.png)]
提示: 无论使用函数级别还是类级别,最后常用场景为: 初始化: 1. 获取浏览器实例化对象 2. 最大化浏览器 3. 隐式等待 结束: 关闭浏览器驱动对象五、断言 ☆
1、什么是断言:
让程序代替人工自动的判断预期结果和实际结果是否相符
断言的结果:
1)、True,用例通过
2)、False,代码抛出异常,用例不通过
3)、在unittest中使用断言,需要通过 self.断言方法
2、为什么要断言:
自动化脚本执行时都是无人值守,需要通过断言来判断自动化脚本的执行是否通过
注:自动化脚本不写断言,相当于没有执行测试一个效果。
3、常用的断言:
self.assertEqual(ex1, ex2) # 判断ex1 是否和ex2 相等self.assertIn(ex1, ex2) # ex2是否包含 ex1 注意:所谓的包含不能跳字符self.assertTrue(ex) # 判断ex是否为True重点讲前两个assertEqual 和 assertIn方法:assertEqual:self.assertEqual(预期结果,实际结果) 判断的是预期是否相等实际assertIn:self.assertIn(预期结果,实际结果) 判断的是预期是否包含实际中assertIn('admin', 'admin') # 包含assertIn('admin', 'adminnnnnnnn') # 包含assertIn('admin', 'aaaaaadmin') # 包含assertIn('admin', 'aaaaaadminnnnnnn') # 包含assertIn('admin', 'addddddmin') # 不是包含# Login 函数我已经封装好了,这里直接导包调用就可以了。import unittestfrom login import Loginclass TestLogin(unittest.TestCase): """正确的用户名和密码: admin, 123456, 登录成功""" def test_success(self): self.assertEqual('登录成功', Login('admin', '123456')) def test_username_error(self): """错误的用户名: root, 123456, 登录失败""" self.assertEqual('登录失败', Login('root', '123456')) def test_password_error(self): """错误的密码: admin, 123123, 登录失败""" self.assertEqual('登录失败', Login('admin', '123123')) def test_error(self): """错误的用户名和错误的密码: aaa, 123123, 登录失败""" # self.assertEqual('登录失败',Login('登陆失败','123123')) self.assertIn('失败', Login('登录失败', '123123'))六、跳过
对于一些未完成的或者不满足测试条件的测试函数和测试类, 不想执行,可以使用跳过
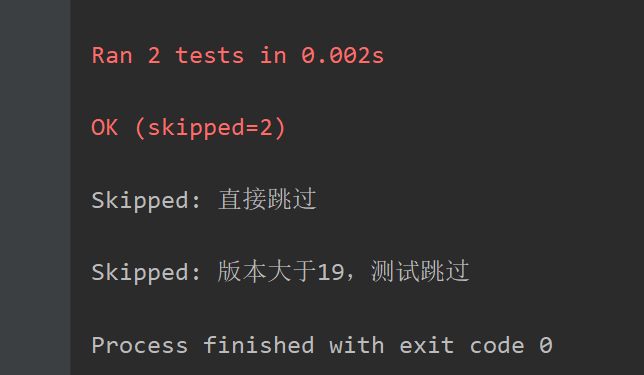
"""使用方法,装饰器完成代码书写在 TestCase 文件"""# 直接将测试函数标记成跳过@unittest.skip('跳过条件')# 根据条件判断测试函数是否跳过 , 判断条件成立, 跳过@unittest.skipIf(判断条件,'跳过原因')import unittestversion = 20class TestDemo1(unittest.TestCase): @unittest.skip('直接跳过') def test_method1(self): print('测试用例1-1') @unittest.skipIf(version >19, '版本大于19,测试跳过') def test_method2(self): print('测试用例1-2')结果:
七、数据驱动(unittest ddt)☆
ddt:data-driver tests
数据驱动: 是以数据来驱动整个测试用例的执行, 也就是测试数据决定测试结果
数据驱动解决的问题是:
1)、代码和数据分离,避免代码冗余
2)、不写重复的代码逻辑;
在python解释器中需要安装 ddt 这个包才能用:
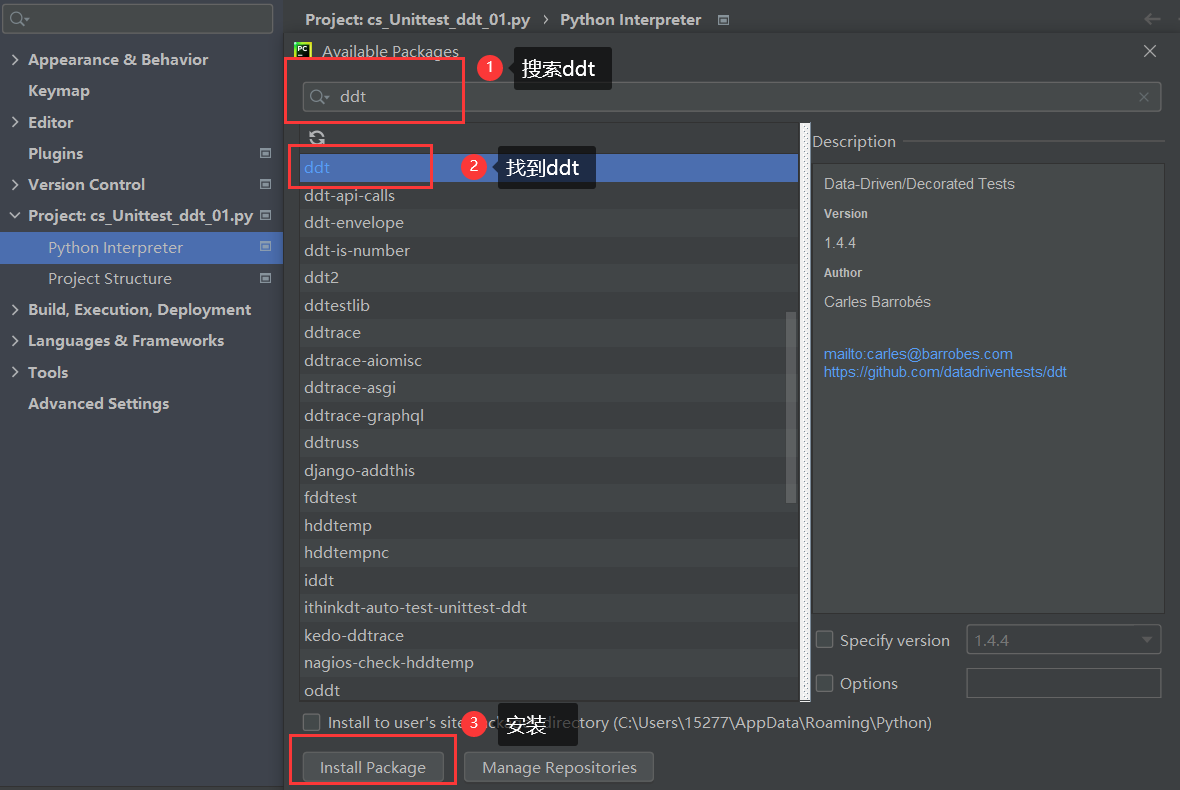

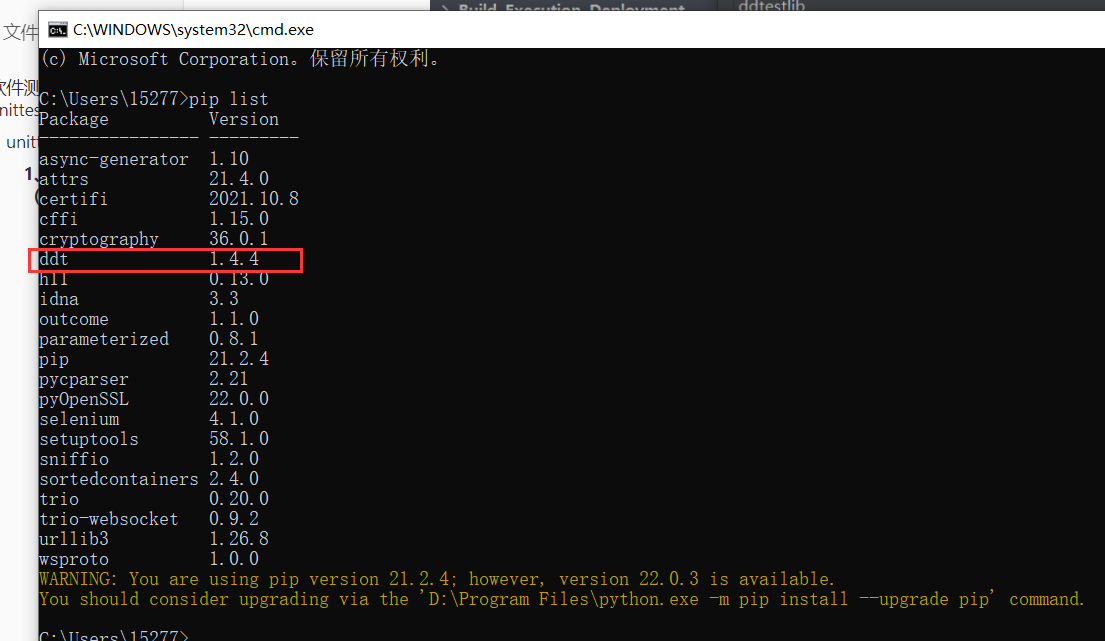
要检查是否安装上,在cmd当中 输入 pip list命名,有ddt说明安装成功
语法:
1、使用数据驱动,要在class前加上修饰器 @ddt
说明:方法里面使用 print ,为了方便,模拟测试用例,主要是为了学习数据驱动,实际中方法里面写的是测试用例的代码
import unittestfrom ddt import ddt, data@ddt class TestDemo(unittest.TestCase): # 单一参数 @data('17611110000', '17611112222') def test_1(self, phone): print('测试一电话号码:', phone) if __name__ == '__main__': unittest.main()else: pass1)、结合 selenium 使用 ddt
"""unittest + selenium"""import unittestfrom time import sleepfrom ddt import ddt, datafrom selenium import webdriver@ddtclass TestBaidu(unittest.TestCase): def setUp(self) ->None: self.driver = webdriver.Chrome() self.driver.get('https://www.sogou.com/') def tearDown(self) ->None: sleep(3) self.driver.quit() # 单一参数 @data('易烊千玺', '王嘉尔') def test_01(self, name): self.driver.find_element_by_id('query').send_keys(name) self.driver.find_element_by_id('stb').click()if __name__ == '__main__': unittest.main()self:相当于java中的this,当前对象的引用,self.driver定义了driver这个变量。
2、在实际中不可能是单一参数进行传参,将会使用多个参数进行传参:
注意事项:1)、多个数据传参的时候@data里面是要用列表形式2)、会用到 @unpack 装饰器 进行拆包,把对应的内容传入对应的参数;import unittestfrom ddt import ddt, data, unpack@ddtclass TestDemo(unittest.TestCase): # 多参数数据驱动 @data(['admin', '123456']) # unpack 是进行拆包,不然会把列表里面的数据全部传到username这个一个参数,我们要实现列表中的两个数据分别传入对应的变量中 @unpack def test_2(self, username, password): print('测试二:', username, password)if __name__ == '__main__': unittest.main()else: pass 但是以上步骤都是数据在代码当中的,假如要测试n个手机号这样的数据,全部写在 @data 装饰器里面就很麻烦,这就引出了数据驱动里面的代码和数据的分离。
3、将数据放入一个文本文件中,从文件读取数据, 如JSON、 excel、 xml、 txt等格式文件 ,这里演示的是json文件类型.
json文件处理, 这个链接介绍了json文件和Python文件基本操作
(1)、在json文件驱动
[ { "username": "admin", "password": "123456" }, { "username": "normal", "password": "45678" }](2)、在测试代码中读取json文件
import jsonimport unittestfrom ddt import ddt, data, unpack# 用json多个参数读取def reads_phone(): with open('user.json', encoding='utf-8') as f: result = json.load(f) # 列表 return result @ddtclass TestDemo(unittest.TestCase): # 多参数数据驱动 @data(*reads_phone()) # unpack 是进行拆包,不然会把列表里面的数据全部传到username这个一个参数,我们要实现列表中的两个数据分别传入对应的变量中 @unpack def test_2(self, username, password): print('测试二:', username, password)if __name__ == '__main__': unittest.main()else: pass注意事项:1、with open里面默认是 ”r“ 2、@data 里面的 * 含义是实现每个json对象单个传入方法执行,不然会吧json文件里面所用数据全部传入 >* 是元祖; >** 是字典;3、参数不能传错,要对应执行结果:
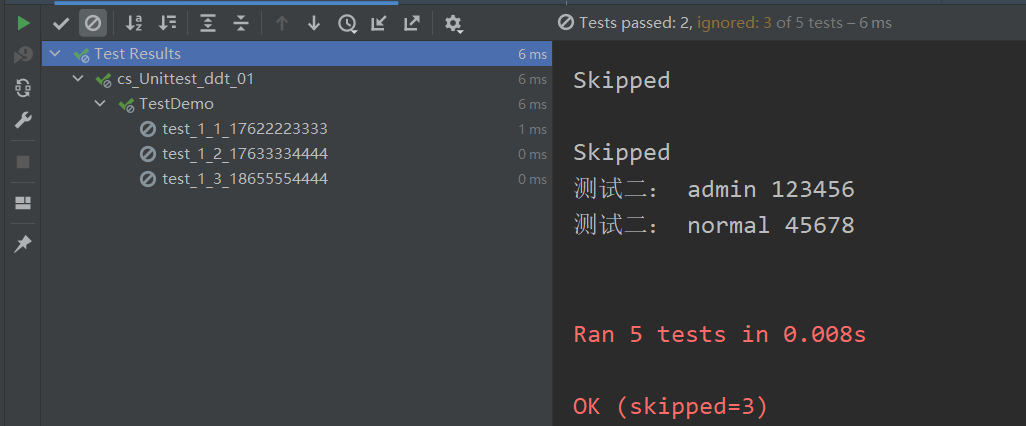
(3)、txt文件驱动
一行表示一组:
admin,123456normal,456789import unittestdef read(): lis = [] with open('readtext.txt', 'r', encoding='utf-8') as f: for line in f.readlines(): # lis.append(line) # ['admin,123456\n', 'normal,456789\n'] # lis.append(line.strip('\n')) ['admin,123456', 'normal,456789'] 两个字符串 lis.append(line.strip('\n').split(',')) # [['admin', '123456'], ['normal', '456789']] return lisclass TestDome(unittest.TestCase): def test_01(self): li = read() print(li)if __name__ == '__main__': unittest.main()"""split():一个字符串里面用某个字符分割,返回列表strip():去掉两边的字符或者字符串,默认删除空白符(包括'\n', '\r', '\t', ' ')"""(3)、csv 文件驱动
供应商名称,联系人,移动电话英业达,张三,13261231234阿里巴巴,李四,13261231231日立公司,王五,13261231233写法一:
"""编写 csvv.py脚本读取csv中的测试数据"""import csvclass ReadCsv(): def read_csv(self): lis = [] # 用csv的API的reader方法!!!! data = csv.reader(open('testdata.csv', 'r')) #!!!! next(data, None) for line in data: lis.append(line) # lis.append(line[0]) # 二维数组可以省略行,列不可以省略 # lis.append(line[1]) return lis# 实例化类readCsv = ReadCsv()# 打印类中的方法print(readCsv.read_csv())
写法二: 推荐
def csvTest(): li = [] with open('user.csv', 'r', encoding='utf-8') as f: filename = csv.reader(f) next(filename, None) for r in filename: li.append(r) return li(4) 、yaml文件驱动
- username: admin9 password: 123456- username: normal password: 789456- 对应的json文件
[ { "username": "admin9", "password": 123456 }, { "username": "normal", "password": 7894 }]写法:
"""使用yaml数据驱动"""import unittestfrom time import sleepfrom selenium import webdriverfrom ddt import ddt, data, unpack, file_data@ddtclass YamlTest(unittest.TestCase): def setUp(self) ->None: self.driver = webdriver.Chrome() self.driver.get('file:///D:/%E6%A1%8C%E9%9D%A2/page/%E6%B3%A8%E5%86%8CA.html') self.driver.maximize_window() def tearDown(self) ->None: driver = self.driver sleep(3) driver.quit() # file_data 传入多个参数的时候,@unpack 的解包不起作用 @unittest.skip @file_data('../user.yaml') @unpack def test_yaml01(self, username, password): driver = self.driver driver.find_element_by_id('userA').send_keys(username) driver.find_element_by_id('passwordA').send_keys(password) # 注意:传的参数名称要与yaml文件对应 # 在yaml数据中文件中采用对象(键值对)的方式来定义数据内容 @file_data('../user1.yaml') def test_yaml02(self, username, password): driver = self.driver driver.find_element_by_id('userA').send_keys(username) driver.find_element_by_id('passwordA').send_keys(password)if __name__ == '__main__': unittest.main()注意:file_date 装饰器,可以直接读取yaml和json文件
(4)、Excel文件驱动
建立excel表的时候需要退出pychram在根目录下创建excel表保存,否则会报错
def read_excel(): xlsx = openpyxl.load_workbook("../excel.xlsx") sheet1 = xlsx['Sheet1'] print(sheet1.max_row) # 行 print(sheet1.max_column) # 列 print('=======================================================') allList = [] for row in range(2, sheet1.max_row + 1): rowlist = [] for column in range(1, sheet1.max_column + 1): rowlist.append(sheet1.cell(row, column).value) allList.append(rowlist) return allList用excel登录csdn操作
"""测试excel数据驱动"""import unittestfrom time import sleepimport openpyxl as openpyxlfrom ddt import ddt, data, unpackfrom selenium import webdriver# 读取excel表中的数据,使用xlrd,openpyxldef read_excel(): xlsx = openpyxl.load_workbook("../excel.xlsx") sheet1 = xlsx['Sheet1'] print(sheet1.max_row) # 行 print(sheet1.max_column) # 列 print('=======================================================') allList = [] for row in range(2, sheet1.max_row + 1): rowlist = [] for column in range(1, sheet1.max_column + 1): rowlist.append(sheet1.cell(row, column).value) allList.append(rowlist) return allList@ddtclass ExcelText(unittest.TestCase): def setUp(self) ->None: self.driver = webdriver.Chrome() self.driver.get('https://passport.csdn.net/login?code=applets') self.driver.maximize_window() def tearDown(self) ->None: driver = self.driver sleep(3) driver.quit() @data(*read_excel()) @unpack def test_excel01(self, flag, username, password): print(flag, username, password) driver = self.driver sleep(2) driver.find_element_by_xpath('/html/body/div[2]/div/div[2]/div[2]/div[1]/div/div[1]/span[4]').click() driver.find_element_by_xpath('/html/body/div[2]/div/div[2]/div[2]/div[1]/div/div[2]/div/div[1]/div/input').send_keys(username) driver.find_element_by_xpath('/html/body/div[2]/div/div[2]/div[2]/div[1]/div/div[2]/div/div[2]/div/input').send_keys(password) driver.find_element_by_xpath('/html/body/div[2]/div/div[2]/div[2]/div[1]/div/div[2]/div/div[4]/button').click()if __name__ == '__main__': unittest.main()十、截图操作
用例不可能每一次运行都成功,肯定运行时候有不成功的时候。如果可以捕捉到错误,并且把错误截图保存,这将
是一个非常棒的功能,也会给我们错误定位带来方便
截图方法:driver.get_screenshot_as_file
"""捕捉异常截图测试"""import os.pathimport timeimport unittestfrom time import sleepfrom selenium import webdriverclass ScreeshotTest(unittest.TestCase): def setUp(self) ->None: self.driver = webdriver.Chrome() self.driver.get('https://www.sogou.com/') self.driver.maximize_window() def tearDown(self) ->None: sleep(3) driver = self.driver driver.quit() def test_01(self): driver = self.driver driver.find_element_by_id('query').send_keys("易烊千玺") driver.find_element_by_id('stb').click() sleep(3) print(driver.title) try: self.assertEqual(driver.title, u"搜狗一下你就知道", msg="不相等") except: self.saveScreenShot(driver, "shot.png") sleep(5) def saveScreenShot(self, driver, filename): if not os.path.exists("./imge"): os.makedirs("./imge") # 格式十分重要,小写大写敏感 %Y%m%d-%H%M%S now = time.strftime("%Y%m%d-%H%M%S", time.localtime(time.time())) driver.get_screenshot_as_file("./imge/" + now + "-" + filename) sleep(3)if __name__ == '__main__': unittest.main()九、测试报告
有两种测试报告:
1、自带的测试报告
2、生成第三方测试报告
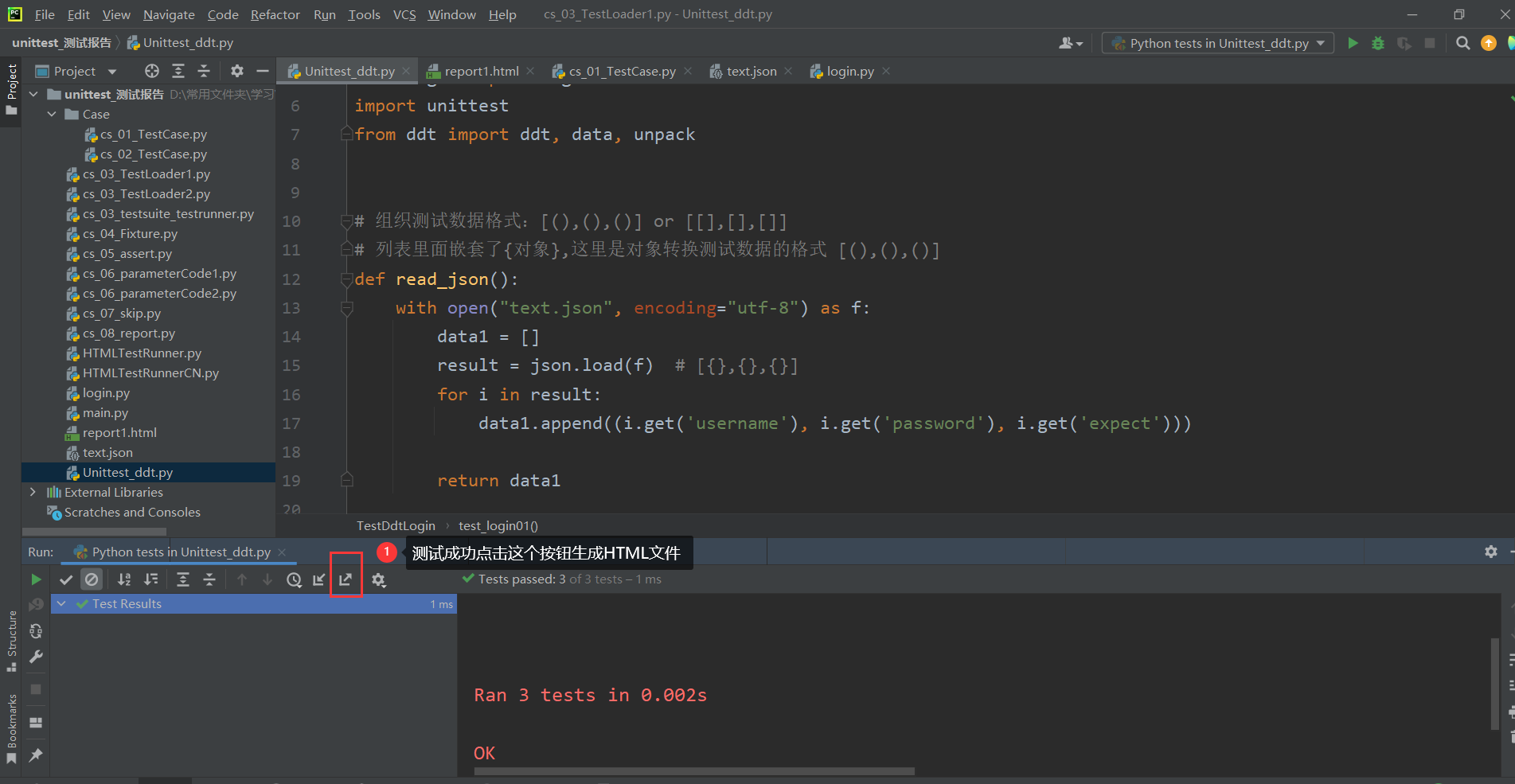
9.1 自带测试报告
只有单独运行 TestCase 的代码,才会生成测试报告
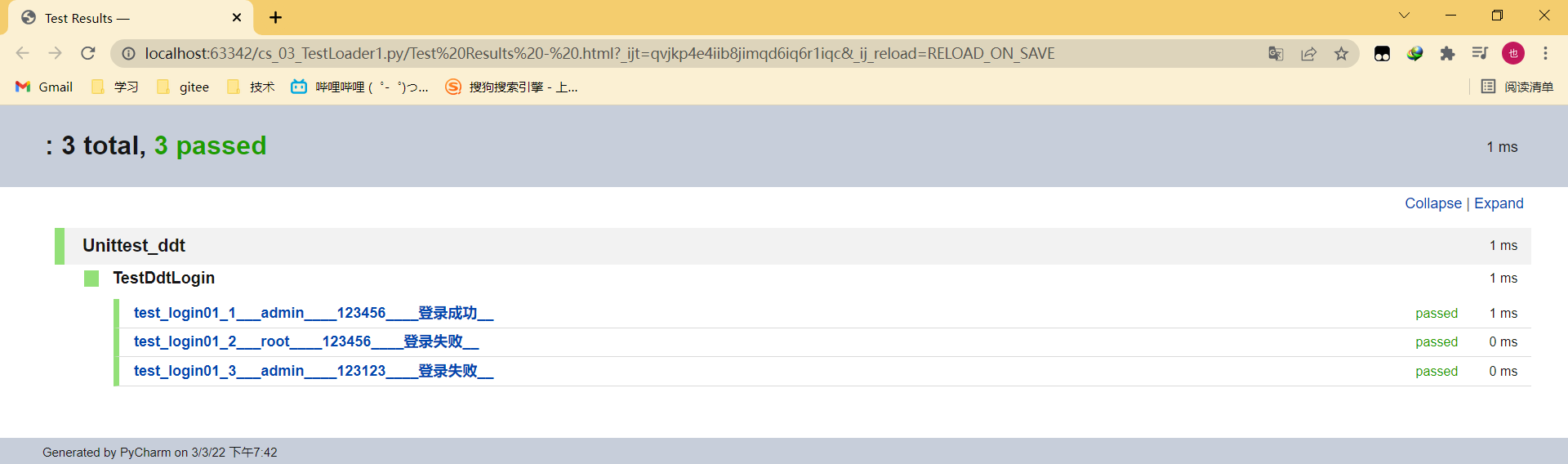
9.2 生成第三方测试报告
这里需要第三方的测试运行类模块,然后放在代码的目录中

就像这两个模块一样放进代码目录中
步骤: 1. 获取第三方的 测试运行类模块 , 将其放在代码的目录中 2. 导包 unittest 3. 使用 套件对象, 加载对象 去添加用例方法 4. 实例化 第三方的运行对象 并运行 套件对象 HTMLTestRunner()写法一:
import unittestfrom HTMLTestRunner import HTMLTestRunnersuite = unittest.defaultTestLoader.discover('.', 'Uni*.py')file = 'report1.html'with open(file, 'wb') as f: runner = HTMLTestRunner(f, 2, '测试报告', 'python3.10') # 运行对象 # 运行对象执行套件, 要写在 with 的缩进中 runner.run(suite)写法二:
"""生成测试报告"""import os.pathimport sysimport timeimport unittestfrom time import sleepfrom HTMLTestRunner import HTMLTestRunnerdef createsuite(): discovers = unittest.defaultTestLoader.discover("./cases", pattern="cs*.py") print(discovers) return discoversif __name__ == '__main__': # 当前路径 # sys.path 是一个路径的集合 curpath = sys.path[0] print(sys.path) print(sys.path[0]) # 当前路径文件resultreport不存在时,就创建一个 if not os.path.exists(curpath+'/resultreport'): os.makedirs(curpath+'/resultreport') # 2、解决重名问题 now = time.strftime("%Y-%m-%d-%H %M %S", time.localtime(time.time())) print(time.time()) print(time.localtime(time.time())) # 文件名是 路径 加上 文件的名称 filename = curpath+'/resultreport/'+now+'resultreport.html' # 打开文件html,是用wb以写的方式打开 with open(filename, 'wb') as f: runner = HTMLTestRunner(f, 2, u"测试报告", u"测试用例情况") suite = createsuite() runner.run(suite)这里面的当前路径也可以用 ./来表示!!!
"""生成测试报告"""import os.pathimport sysimport timeimport unittestfrom time import sleepfrom HTMLTestRunner import HTMLTestRunnerdef createsuite(): discovers = unittest.defaultTestLoader.discover("./cases", pattern="cs*.py") print(discovers) return discoversif __name__ == '__main__': # 当前路径文件resultreport不存在时,就创建一个 if not os.path.exists('./resultreport'): os.makedirs('./resultreport') # 2、解决重名问题 # 格式十分重要 %Y-%m-%d-%H %M %S now = time.strftime("%Y-%m-%d-%H %M %S", time.localtime(time.time())) print(time.time()) print(time.localtime(time.time())) # 文件名是 路径 加上 文件的名称 filename = './resultreport/'+now+'resultreport.html' # 打开文件html,是用wb以写的方式打开 with open(filename, 'wb') as f: runner = HTMLTestRunner(f, 2, u"测试报告", u"测试用例情况") suite = createsuite() runner.run(suite)注意:
实例化 第三方的运行对象,HTMLTestRunner()的初始化有多种可以自定义设置

HTMLTestRunner() 1、stream=sys.stdout, 必填,测试报告的文件对象(open ), 注意点,要使用 wb 打开 2、verbosity=1, 可选, 报告的详细程度,默认 1 简略, 2 详细 3、title=None, 可选, 测试报告的标题 4、description=None 可选, 描述信息, Python 的版本, pycharm 版本最后生成结果:
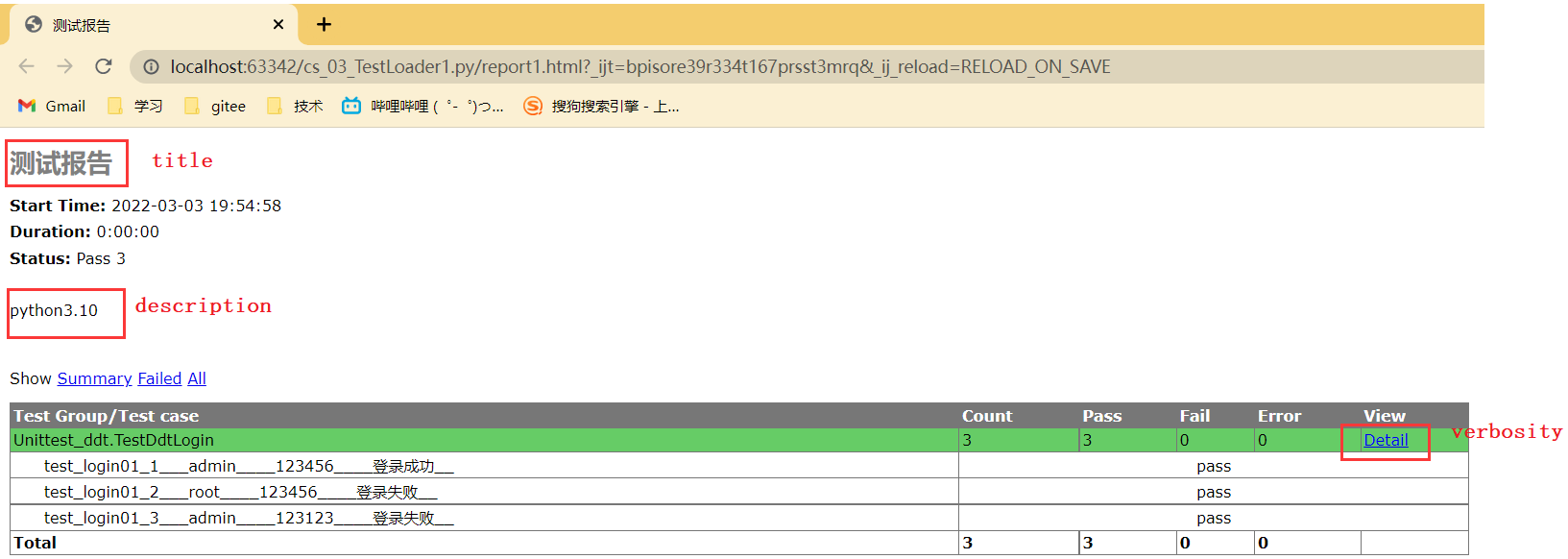
unittest框架就本上就是这些知识了,里面记得东西很多,多敲代码,形成记忆,自动化测试后面还剩下selenium,selenium完了过后基本上自动化的内容差不多就结束了,铁汁们,觉得笔者写的不错的可以点个赞哟❤🧡💛💚💙💜🤎🖤🤍💟,收藏关注呗,你们支持就是我写博客最大的动力!!!!















